








Stable Diffusionを使った動画生成をローカル環境で行いたいと考えているけれど、具体的なやり方や必要なPCスペックが分からずに迷っていませんか。2025年現在、AI動画生成の世界は急速に進化しており、適切なグラボやパソコンさえ用意すれば、誰でも自宅でプロ並みの映像を作り出せるようになっています。クラウドサービスも便利ですが、月額コストや表現の制限を気にせず、自分の好きなだけ試行錯誤できるのはローカル環境ならではの特権です。この記事では、最新の推奨スペックから、低スペックな環境でも動かすための設定、そして導入手順までを徹底的に解説します。
この記事のポイント
- 2025年最新の動画生成に必要なPCスペックと推奨グラフィックボードが分かります
- VRAM不足を解消して低スペックPCでも動画生成を楽しむ方法を学べます
- 主流となっているComfyUIの導入手順と環境構築の流れを把握できます
- Wan 2.1やAnimateDiffなど目的に合わせたモデルの選び方が理解できます
Stable Diffusionの動画生成をローカル環境で始める
ここでは、これからローカル環境での動画生成に挑戦する方に向けて、失敗しないためのハードウェア選びや、最初に準備すべきソフトウェア環境について、基礎から分かりやすく解説していきます。
必要なPCスペックと推奨グラボの選び方
2025年の今、ローカル環境で快適に動画生成を行うために最も重要なパーツは、間違いなくグラフィックボード(GPU)です。特に注目すべきは、GPUに搭載されているVRAM(ビデオメモリ)の容量です。なぜなら、静止画の生成とは異なり、動画生成AIは「時間軸(Temporal)」方向の情報を計算処理する必要があるからです。数秒間の動画であっても、AIは数十枚から百枚以上の画像を連続性を持って生成しなければならず、その計算過程で発生する「中間潜在変数(Latent features)」と呼ばれるデータがVRAMを大量に消費します。
現状の最適解と言えるのは、VRAM 24GB以上を搭載したNVIDIA GeForce RTX 4090や、最新のRTX 5090です。これらがあれば、話題の「Wan 2.2」や「HunyuanVideo」といった高性能な最新モデルを、画質を落とすことなくフルスペック(FP16/BF16精度)で動かすことができます。特にRTX 5090の32GBという容量は、複数のモデルを同時に展開したり、長尺の動画を一気に生成したりする際に圧倒的な余裕をもたらし、クリエイティブな作業を中断させません。
予算を抑えたい場合でも、最低ラインとしてVRAM 16GB(RTX 4080 SUPERやRTX 5080など)は確保したいところです。16GBあれば、後述する軽量化技術を駆使することで、最新モデルの高品質版を動作させることが十分に可能です。一方で、12GB以下のモデル(RTX 3060/4060など)では、生成できる解像度が低くなったり、動作自体が非常に遅くなったりといった制約が厳しくなることを覚悟しておく必要があります。
また、GPUと同じくらい見落としがちなのがシステムメモリ(RAM)です。巨大な動画生成モデル(例えばWan 2.1の14Bモデルなど)をSSDから読み込む際、データは一時的にシステムメモリ上に展開されてからVRAMへと転送されます。このとき、システムメモリが不足していると、PC全体の動作がフリーズしたり、モデルのロードが途中で強制終了したりする原因になります。そのため、最低でも64GB、できれば128GBのメモリを積んでおくことを強くおすすめします。ストレージに関しても、数十GB単位のモデルファイルを頻繁に読み書きするため、HDDではなく高速なNVMe SSD(Gen4以上推奨)が必須です。

- 最高品質・プロ志向: RTX 5090 (32GB) / RTX 4090 (24GB) + メモリ64GB〜128GB
※ストレスフリーで試行錯誤したいならこのクラスが理想。 - コストパフォーマンス重視: RTX 4080 / 5080 (16GB) + メモリ64GB
※工夫次第でハイエンドに迫る出力が可能。現在のボリュームゾーン。 - 入門・実験用: RTX 4060 Ti (16GB) / RTX 3060 (12GB) + メモリ32GB以上
※最新モデルは軽量化必須だが、学習用としては十分機能する。
(出典:NVIDIA『GeForce RTX 40 シリーズ グラフィックス カード』)
VRAM不足を解消する低スペック向け設定
「最新の動画生成モデルを使いたいけれど、手持ちのグラボはVRAM 12GBや16GBしかない…」と諦める必要は全くありません。むしろ、ローカルAIコミュニティの真骨頂は、こうした制約のあるハードウェアでいかに高性能なモデルを動かすかという「最適化技術」の充実にあります。
RTX 3060や4060 TiといったミドルレンジのGPUでも、以下の3つの主要なテクニックを駆使することで、RTX 4090ユーザーと同じモデルを動かし、驚くほど高品質な動画を作り出すことが十分に可能です。
①「GGUF」量子化モデルの活用
現在のローカル環境において最も効果的なのが、「GGUF」形式によるモデルの量子化(Quantization)です。通常、AIモデルは「FP16(16ビット)」というデータ形式で配布されていますが、これを「8ビット」や「4ビット」に圧縮することで、画質の劣化を最小限に抑えつつ、VRAM使用量を半分以下に削減できます。
例えば、Wan 2.1の14Bモデルをオリジナルのまま動かすには約30GB近いVRAMが必要ですが、GGUF版を使えば以下のように劇的に軽量化されます。
| 量子化タイプ | 画質レベル | 必要VRAM目安 (14Bモデル) | 推奨ユーザー |
|---|---|---|---|
| FP16 (Original) | 最高(無劣化) | 約 28GB 〜 32GB | RTX 5090 / 6000 Ada |
| Q8_0 (8bit) | 極めて高い(ほぼ区別不能) | 約 16GB 〜 20GB | RTX 4090 / 3090 |
| Q4_K_M (4bit) | 高い(推奨スタンダード) | 約 10GB 〜 12GB | RTX 4070 / 4060 Ti |
| Q2_K (2bit) | 並(劣化あり) | 約 6GB 〜 8GB | RTX 3060 / 2060 |
ComfyUIでは「ComfyUI-GGUF」カスタムノードを導入することで、これらのモデルを簡単にロードできます。まずは「Q4_K_M」を試してみて、動けばそのまま、厳しければ「Q3」や「Q2」へと下げていくのが定石です。

②テキストエンコーダーの軽量化とオフロード
動画生成モデル(特にWanやHunyuan)が重い理由の一つに、プロンプトを理解するための「テキストエンコーダー(T5-XXLなど)」が巨大である点が挙げられます。これだけでVRAMを10GB以上消費することもあります。
ここでの対策は2つあります。
- FP8版エンコーダーを使う: テキストエンコーダー自体も軽量化されたファイル(例:
umt5_xxl_fp8_e4m3fn.safetensors)を使用することで、精度を落とさずにサイズを半減できます。 - CPUオフロード設定: ComfyUIのモデルロード設定(Load Checkpointなど)や起動オプション(
--lowvram)を活用し、テキスト処理をVRAMではなくシステムメモリ(RAM)で行わせます。生成速度は多少落ちますが、VRAMの空き容量を画像生成そのものに全振りできるため、エラー回避に絶大な効果があります。
③「Tiled VAE」で最後のフリーズを防ぐ
「生成プログレスバーが100%になった瞬間にPCが固まって落ちた」という経験はありませんか? これは、生成された内部データを動画ファイルとして書き出す「VAEデコード」の瞬間に、VRAMが一気に溢れるために起こります。
これを防ぐ特効薬が「Tiled VAE(タイル化デコード)」です。画像を一度に処理するのではなく、小さなタイル状に分割して順番に処理する手法です。処理時間は少し伸びますが、VRAM使用量をピーク時の半分〜3分の1程度に抑えることができます。ComfyUIでは標準で対応している場合が多いですが、専用のノード(VAE Decode Tiledなど)を使うことで、より確実にVRAM不足によるクラッシュを防ぐことができます。
「低解像度(480p/720p)で生成して、後からアップスケールする」ことこそが、VRAM節約と高画質を両立する最短ルートです。最初から高解像度を目指さず、まずは小さなサイズで試行錯誤しましょう。
ComfyUIの導入方法と環境構築の流れ
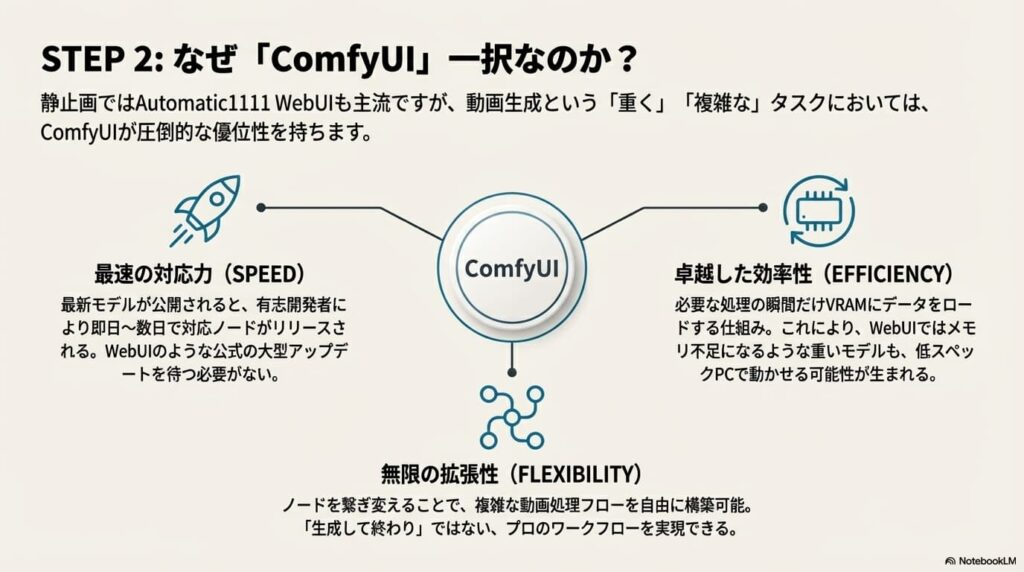
かつて画像生成AIと言えば「Automatic1111 WebUI」が代名詞でしたが、動画生成の分野において現在、「ComfyUI」が圧倒的なシェアと支持を確立しています。その理由は、動画生成特有の「重さ」と「複雑さ」にあります。
ComfyUIは、処理の各工程(モデルの読み込み、プロンプト解釈、サンプリング、動画エンコードなど)を「ノード」と呼ばれる箱で可視化し、それらをケーブルで繋いで自由自在に処理の流れ(ワークフロー)を構築できるツールです。必要な瞬間にだけメモリを確保し、使い終わったら即座に解放するという優れたメモリ管理機能を持っているため、VRAM消費が激しい動画生成においては、WebUIと比較して動作の軽快さと安定性が段違いです。
「ノードとか難しそう…」と身構える必要はありません。以下の手順通りに進めれば、誰でも最短15分ほどで環境を構築できます。
手順①:Windows用「Portable版」の入手(推奨)
初心者の方が最も躓きにくいのが、必要な機能が全てパッケージ化された「Portable(ポータブル)版」を使用する方法です。これを使えば、Pythonなどの複雑なインストール作業をスキップして、ダウンロードして解凍するだけで即座に起動できます。
- GitHubからダウンロード: ComfyUIの公式GitHubページ(Releasesセクション)にアクセスし、
ComfyUI_windows_portable_nvidia...7zというファイルをダウンロードします。ファイルサイズが大きいので注意してください。 - 解凍して配置: ダウンロードしたファイルを、SSD(CドライブやDドライブの直下など、日本語が含まれないパス)に解凍します。フォルダ名は「ComfyUI_windows_portable」のままでOKです。
- 起動確認: フォルダ内にある
run_nvidia_gpu.batをダブルクリックします。黒い画面(コンソール)が立ち上がり、しばらくしてブラウザにComfyUIの画面が表示されれば成功です。
(出典:GitHub『ComfyUI Official Repository』)
手順②:必須機能「ComfyUI Manager」の導入
初期状態のComfyUIは非常にシンプルですが、動画生成を行うには機能不足です。そこで、拡張機能をスマホアプリのように簡単にインストールできるようにする管理ツール「ComfyUI Manager」を導入します。
- ComfyUIのインストールフォルダ内の
ComfyUI/custom_nodesフォルダを開きます。 - そのフォルダ内で右クリックし、「ターミナルで開く」を選択します。
- 黒い画面で
git clone https://github.com/ltdrdata/ComfyUI-Manager.gitと入力してEnterキーを押します。
※PCに「Git」がインストールされていない場合は、先にGit公式サイトからインストールしておく必要があります。 - ComfyUIを再起動すると、メニューに「Manager」ボタンが追加されます。
手順③:動画生成のための「三種の神器」ノードを追加
Managerが導入できたら、メニューの「Manager」ボタンをクリックし、「Install Custom Nodes」から以下の3つの拡張機能を検索してインストールしてください。これらは2025年の動画生成における必須セットです。
| 拡張機能名 | 役割と重要性 |
|---|---|
| ComfyUI-VideoHelperSuite | 動画の読み込み(Load Video)や、生成した画像を動画として保存(Video Combine)するために必須の基本ツール群。 |
| ComfyUI-WanVideoWrapper | 最新の「Wan 2.1 / 2.2」モデルを動かすための専用ラッパー。これを入れるだけで複雑な設定なしにWanモデルが扱えるようになります。(作者: Kijai氏などが有名) |
| ComfyUI-GGUF | 低スペックPCの救世主。VRAM使用量を抑えた「量子化モデル(GGUF形式)」を読み込むために必要です。 |
手順④:ワークフローの読み込み(魔法のドラッグ&ドロップ)
最後に、実際に動画を作るための設計図(ワークフロー)を読み込みます。ComfyUIの最大の特徴は、「生成された画像や、ネットで配布されているワークフロー画像を、ブラウザ画面にドラッグ&ドロップするだけで、同じ環境が再現される」という点です。
CivitaiやHugging Face、あるいは解説ブログなどで配布されている「Wan 2.2 I2V Workflow.json」や「メタデータ付きのPNG画像」を探してダウンロードし、ComfyUIの画面に放り込んでみてください。一瞬でノードが組み上がり、あとはモデルファイルの場所を指定するだけで動画生成を開始できます。「自分でゼロから組む」必要は全くありません。まずは先人の知恵を借りて、とにかく動かしてみることから始めましょう。
WebUIとComfyUIのどっちが良いか比較
これから本格的に動画生成を始めようとする方が直面する最大の分岐点が、使い慣れた「Automatic1111 WebUI(WebUI Forgeを含む)」を使い続けるか、新興勢力の「ComfyUI」に乗り換えるかという選択です。
結論から断言します。動画生成をメインに据えるのであれば、迷わず「ComfyUI」を選んでください。これは単なる好みの問題ではなく、動画生成という「重く、複雑で、進化の速い」タスクにおいて、ComfyUIだけが持つ構造的な優位性が不可欠だからです。
① 最新技術への対応スピードが段違い
2025年のAI動画界隈は、週単位で新しいモデルが登場するほどの激動期です。「Wan 2.1/2.2」や「HunyuanVideo」といった革新的なオープンソースモデルが登場した際、その当日に使えるようになるのはほぼ間違いなくComfyUIです。
これは、ComfyUIが機能単位(ノード)で開発されているため、有志の開発者が「そのモデルを動かすためのノード」を単体でリリースできるからです。一方、WebUIはシステム全体に統合する必要があるため、対応に数週間〜数ヶ月のラグが生じたり、そもそも重すぎて実装が見送られたりすることが珍しくありません。「最新の技術をすぐに試したい」という動画クリエイターにとって、このタイムラグは致命的です。
② 決定的な差を生む「VRAM管理」の仕組み
動画生成は、静止画生成の数十倍のVRAM(ビデオメモリ)を消費します。ここで両者の設計思想の違いが露骨に現れます。
- WebUIの挙動: 必要なモデルやデータを一度にVRAMに展開しようとする傾向があり、メモリピークが高くなりがちです。結果として「Out of Memory」エラーで落ちやすくなります。
- ComfyUIの挙動: 処理を細切れの「バケツリレー」のように行います。「モデルをロード→計算→不要なデータを即解放→次の処理へ」というサイクルを徹底しているため、同じVRAM容量でも、WebUIでは動かないモデルがComfyUIなら動くという現象が頻発します。
| 比較項目 | Automatic1111 WebUI (Forge含む) | ComfyUI |
|---|---|---|
| 動画生成への適性 | △ 拡張機能(AnimateDiff等)での対応が基本。最新の巨大モデルは動作困難な場合が多い。 | ◎ ネイティブで得意。動画生成フロー(読み込み→加工→結合)が標準で組みやすい。 |
| メモリ効率 (VRAM) | △ メモリ解放が苦手で、長時間稼働すると重くなる。高解像度化で落ちやすい。 | ◎ 必要な時だけメモリを使うため非常に効率的。低スペックGPUの救世主。 |
| 拡張性・自由度 | △ 基本的な機能は揃うが、「ここだけ変えたい」という細かいパイプライン制御が苦手。 | ◎ 無限大。複数のControlNetを複雑に組み合わせたり、独自の処理フローを発明できる。 |
| 学習コスト | ◎ 見た目が分かりやすく、日本語の情報も豊富。直感的に触れる。 | △ ノード(配線)の理解が必要。「難しそう」という第一印象の壁がある。 |
「難しそう」という壁を突破する方法
ComfyUIの最大の懸念点は、スパゲッティのように絡み合ったノード画面の「見た目の難しさ」でしょう。しかし、心配は無用です。動画生成を行うユーザーの9割は、自分でゼロからノードを組んでいるわけではありません。
ComfyUIには、「生成された画像(PNG)をブラウザにドラッグ&ドロップするだけで、その画像を作った設定(ワークフロー)が完全に復元される」という強力な機能があります。つまり、ネット上で上手な人が配布している画像やJSONファイルを拾ってきて、ポンと入れるだけで準備完了なのです。まずは「人の真似」から入り、徐々に数値を変えてみることから始めれば、WebUI以上の快適さを実感できるはずです。
- WebUI: シンプルな美少女イラスト生成や、画像の管理、手軽なInpainting(修正)作業に。
- ComfyUI: 動画生成全般、最新モデルの試用、SDXLやFluxなどの重いモデルの運用に。
無料で使えるおすすめ動画生成モデル
ローカル環境を構築する最大のメリットは、世界中のトップ企業や研究機関が開発した、商用サービスに匹敵(あるいは凌駕)する高性能なAIモデルを、すべて無料でダウンロードして使い倒せることです。これらは「オープンウェイト(Open Weights)」と呼ばれ、自宅のPCさえあれば誰でも最先端の映像技術を享受できます。
2025年現在、動画生成AIの進化は凄まじく、数多くのモデルが公開されていますが、実用レベルで「使える」モデルは以下の3つに集約されます。それぞれの特性を理解し、作りたい映像に合わせて使い分けることが成功への近道です。

① Wan 2.1 / 2.2 (Alibaba Cloud) 〜現在の絶対王者〜
現在、ローカル派の動画クリエイターから最も熱い視線を浴びているのが、Alibaba Cloudが公開した「Wan」シリーズです。このモデルの凄さは、従来の動画生成AIが苦手としていた「物理的な挙動の自然さ」と「破綻のない高画質」を極めて高いレベルで両立している点にあります。
特にハイエンド向けの「14B(140億パラメータ)」モデルは、水しぶき、炎の揺らめき、布の質感などを物理シミュレーション並みにリアルに再現し、映画のワンシーンのような重厚な映像を作り出します。また、一般ユーザー向けに軽量化された「5B」や「1.3B」モデルも用意されており、VRAM 12GBクラスのグラボでも十分に動作するのが魅力です。「実写のようなリアルな動画を作りたい」なら、まずはこのモデルを選べば間違いありません。
② HunyuanVideo (Tencent) 〜芸術性と拡張性の極み〜
Wanシリーズと双璧をなすのが、Tencentの「HunyuanVideo」です。このモデルは、独自の「3D VAE」アーキテクチャを採用しており、色彩の鮮やかさや、幻想的でアーティスティックな表現力においてWanを凌ぐと評価されています。
Hunyuanの最大の特徴は、ユーザーコミュニティによる拡張エコシステムが非常に活発であることです。Civitaiなどのサイトには、特定のアニメスタイルや、特殊なカメラワーク、エフェクトを追加するための「LoRA(追加学習パッチ)」が大量に公開されています。「自分だけのアートスタイルを追求したい」「アニメ調の高品質なMVを作りたい」というクリエイターにとっては、HunyuanVideoが最強のパートナーとなるでしょう。
③ AnimateDiff (Community) 〜キャラクター制御の鉄板〜
こちらは厳密には「新しい動画モデル」ではなく、既存の画像生成AI(Stable Diffusion v1.5やSDXL)に「時間の概念」を追加する拡張モジュールです。しかし、2025年になってもその重要性は失われていません。
その理由はシンプルで、「過去数年間に蓄積された膨大なイラスト生成用の資産がそのまま使える」からです。お気に入りの美少女モデル(Checkpoint)や、特定の衣装を着せるLoRAをそのまま動画化できるのはAnimateDiffだけの特権です。「いつものあのキャラクターを動かしたい」「特定の絵柄を絶対に崩したくない」というニーズにおいては、最新のWanやHunyuanよりも遥かに使い勝手が良いのが実情です。
| モデル名 | 開発元 | 得意ジャンル | こんな人におすすめ |
|---|---|---|---|
| Wan 2.1 / 2.2 | Alibaba | 実写、物理表現、映画的演出 | リアルな映像美を追求したい人、VFX制作者 |
| HunyuanVideo | Tencent | アニメ、芸術、抽象表現 | LoRAで画風をカスタムしたい人、MV制作者 |
| AnimateDiff | Community | キャラクター動画、ループ素材 | 既存のSDイラスト資産を活用したい人 |
これらのモデルは無料でダウンロードできますが、商用利用に関してはそれぞれ規定が異なります(例:クリエイティブ・コモンズ、Apache 2.0、独自の商用利用不可ライセンスなど)。YouTubeでの収益化や業務での利用を考えている場合は、必ず配布元の公式ライセンス条項を確認してください。
Stable Diffusionでの動画生成をローカルで極める
必要な機材を揃え、ComfyUIで環境を構築し、最新のモデルを手に入れました。ここからは、いよいよ実践編です。
しかし、実際に生成ボタンを押してみると、最初は「思ったように動かない」「顔が崩れる」「画質がボヤけている」といった壁にぶつかるはずです。これは、動画生成AIが静止画以上に複雑なパラメータ(変数)を持っているためです。プロンプトだけでなく、フレームレート、モーションの強度、ノイズ除去率、そしてアップスケーリングの手法など、コントロールすべき要素は多岐に渡ります。
ここからのセクションでは、単に「動画を作る」レベルから一歩進んで、「自分の意図通りにコントロールされた、プロフェッショナルな品質の映像作品」へと昇華させるための具体的なテクニックや、現場で使われている最適化のノウハウを深掘りしていきます。これらをマスターすれば、あなたのPCは単なる計算機から、無限の可能性を秘めた映画スタジオへと進化するでしょう。
高画質な動画を作るための具体的なやり方
生成された動画を初めて見たとき、「あれ、思ったより画質が荒い?」「全体的にボヤけている」と感じることがあるかもしれません。しかし、これは決して失敗ではありません。現在の動画生成AIは、計算量の爆発的な増大を防ぐため、ベースとなる生成解像度を480p(854x480)や720p(1280x720)程度に制限しているのが一般的だからです。
この「素材」を、市販のBlu-rayや4K配信に匹敵するプロフェッショナルな品質に引き上げるためには、生成後の後処理(ポストプロセス)が不可欠です。具体的には、解像度を上げる「アップスケーリング」と、動きを滑らかにする「フレーム補間」の2つの工程をワークフローに組み込むことで、劇的な品質向上が可能になります。
① 解像度を上げる「2つのアップスケーリング手法」
ComfyUIで動画を高画質化する場合、主に以下の2つのアプローチを使い分けます。
- Pixel Upscale(ピクセルベース拡大):
生成された画像を画像処理AI(RealESRGANや4x-UltraSharpなど)に通して拡大する方法です。
特徴: 処理が高速でVRAM消費も少ないため、手軽に4K化したい場合に最適です。ただし、元画像にないディテールを「想像して」書き足す能力には限界があります。 - Latent / V2V Upscale(再生成ベース拡大):
一度生成された動画を拡大し、それを「下書き」として再度AI(WanやHunyuanなど)に通し、低いノイズ除去率(Denoise 0.3〜0.4程度)で書き直させる方法です。いわゆる「Hires. Fix」の動画版です。
特徴: 髪の毛の質感や肌のキメなど、驚くほど緻密なディテールが追加されますが、VRAM消費が激増し、設定を間違えると映像がチラつく原因になります。
初心者のうちは、まずPixel Upscale系のノード(Upscale Image (using Model)など)を使い、モデルファイルとして「4x-UltraSharp」を指定するのが最も失敗が少なく、シャープな結果を得られる黄金パターンです。

② ヌルヌル動かす「フレーム補間(Frame Interpolation)」
AIが生成する動画は、通常16fps〜24fps(1秒間に16〜24枚)のカクカクした映像です。これを現代的な60fpsの滑らかな映像に変換する技術がフレーム補間です。
ComfyUIでは、「RIFE (Real-Time Intermediate Flow Estimation)」というアルゴリズムを実装したカスタムノード(ComfyUI-Frame-Interpolation)を使うのが業界標準となっています。これは、前後のフレーム(画像)の動きを解析し、その間に存在すべき「中間の画像」をAIが予測して生成・挿入する技術です。
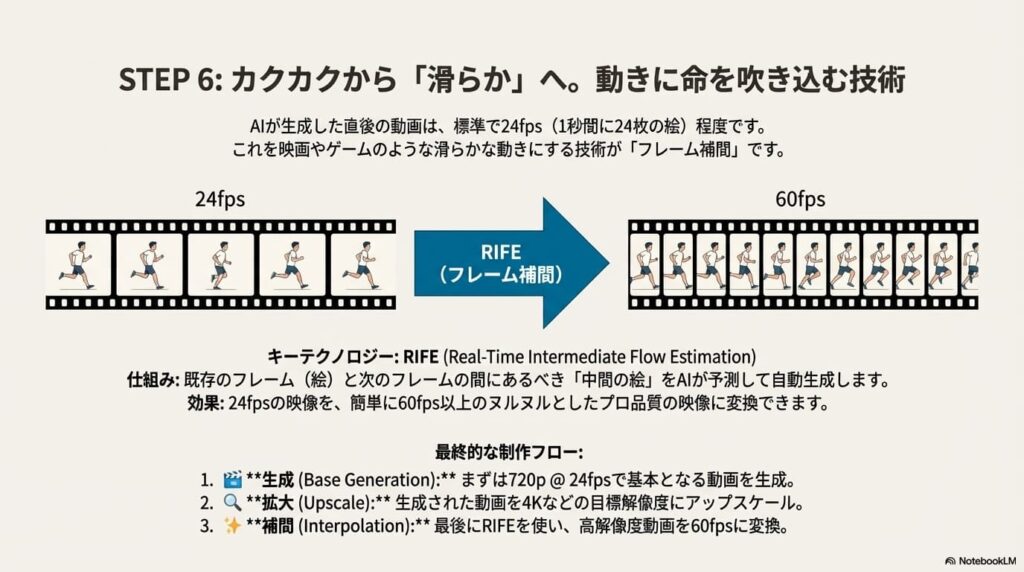
- Base Generation: まずは720p @ 24fps で動画を生成する。
- Upscale: 生成結果を4Kなどの高解像度に拡大する。
- Interpolation: 最後にRIFEを通して 24fps → 60fps に変換する。
※補間処理を先に行うと、枚数が増えた分だけアップスケールの時間が倍増してしまうため、最後に補間するのが効率的です。
これらの処理は、ComfyUIなら一つのワークフロー内にすべて連結して自動化できます。「寝る前にセットして、朝起きたら4K/60fpsの動画ができている」という環境を作れるのが、ローカル運用の最大の強みなのです。
AnimateDiffとWanモデルの使い分け
「最新のWanモデルが高性能なのは分かったけれど、AnimateDiffはもう時代遅れなの?」という疑問を持つ方も多いでしょう。結論から言えば、この2つは競合するものではなく、「目的によって使い分けるべき全く別のツール」と考えるのが2025年の正解です。
両者の決定的な違いは、「絵を動かすアプローチ」にあります。それぞれの特性を深く理解することで、制作の無駄を省き、最短距離で理想の映像にたどり着くことができます。
① AnimateDiff:キャラクターと画風の守護神
AnimateDiffの本質は、動画生成モデルではなく「既存の画像生成モデルに"時間軸"を挿入する拡張プラグイン」である点です。
- 最大の強み: これまでに集めたSD1.5やSDXL用のCheckpoint(モデル)やLoRAがそのまま使えます。「いつものあの子」の顔立ち、衣装、そして繊細なタッチの画風を1ミリも崩さずに動かすことができるのは、現状AnimateDiffだけです。
- 得意な表現: キャラクターのダンス動画、ループするGIFアニメ、特定のアニメスタイルの完全再現。ControlNet(OpenPose)との相性が抜群で、指定した通りのポーズで踊らせる制御力は他の追随を許しません。
- 弱点: カメラがぐるっと回るようなダイナミックな視点移動や、背景が大きく変化するシーンは苦手で、破綻しがちです。
② Wan 2.2 / HunyuanVideo:圧倒的なリアリティと演出力
これらは最初から大量の動画データで学習された「ネイティブ動画生成モデル」です。AIは「物がどう動くか」「光がどう変化するか」という物理法則を理解しています。
- 最大の強み: 破綻のない一貫性と、映画のようなカメラワークです。「ドローンで街を空撮する」「カメラが被写体にズームインしながら回り込む」といった複雑な動きを、プロンプトだけで指示しても完璧にこなします。
- 得意な表現: 実写合成、壮大な風景、映画の予告編のような映像、炎や水などの流体表現。動きの滑らかさと物理的な説得力はAnimateDiffを遥かに凌駕します。
- 弱点: 特定のキャラクター(オリジナルキャラ)の造形を維持するのが難しい点です。LoRAなどによる追加学習なしでは、生成するたびに顔が変わってしまうことがあります。
| 比較軸 | AnimateDiff (v3/v4/Lightning) | Wan 2.2 / HunyuanVideo |
|---|---|---|
| アーキテクチャ | 画像モデル + モーションモジュール | 動画専用 Diffusion Transformer |
| キャラクター固定 | ◎ 完璧(既存LoRA使用可) | △ 難しい(専用LoRA学習が必要) |
| カメラワーク・背景 | △ 苦手(破綻しやすい) | ◎ 得意(映画並みの演出が可能) |
| 制御 (ControlNet) | ◎ OpenPose等で精密制御が可能 | ◯ ポーズや深度は可能だが重い |
| 推奨される用途 | キャラ動画、ダンス、ループ素材、アニメ | CM制作、実写映像、VFX素材、背景動画 |
プロが実践する「ハイブリッド運用」
ComfyUIを使えば、これらを対立させるのではなく、連携させることが可能です。例えば、以下のようなワークフローが実用化されています。
- Wan 2.2でベースを作成: まずWanモデルを使って、実写のようなリアルな動きとカメラワークを持つ動画(原画)を生成します。
- AnimateDiffでスタイル変換: 生成した動画をAnimateDiffのVid2Vid(動画から動画への変換)に入力し、ControlNetで動きを固定しつつ、画風だけを「アニメ調」や「油絵調」に塗り替えます。
このように、「動きはWanに任せ、絵柄はAnimateDiffで整える」という使い分けこそが、2025年のローカル動画生成における最強のメソッドと言えるでしょう。
意図通りに動かすプロンプト入力のコツ
「綺麗な絵は出るけれど、動きがぎこちない」「指示した動きをしてくれない」
これは、動画生成における初心者の最大の悩みです。実は、動画生成AIに対するプロンプト(指示出し)は、静止画生成のそれとは根本的に「文法」が異なります。
静止画(SDXLやPony Diffusionなど)では「1girl, smile, running, masterpiece」といった単語の羅列(タグ形式)が主流ですが、Wan 2.2やHunyuanVideoといった最新の動画モデルに対しては、この方法は通用しません。動画AIを意図通りに動かすためには、あなたが映画監督になりきって、「誰が、どこで、何をしていて、カメラはどう撮っているか」を文章で論理的に説明する必要があります。
① 成功するプロンプトの黄金テンプレート
漫然と単語を並べるのではなく、以下の4つの要素を順番に組み立てる「黄金テンプレート」意識してください。この順序で記述することで、AIはシーンの状況を正確に理解します。
[1. 映像のスタイル] + [2. 被写体とアクション] + [3. 背景と環境] + [4. カメラワークと演出]
- NG例(タグ羅列):
1girl, running, rain, city, night, high quality
→ 情報が断片的で、AIが「どんな状況で走っているか」を補完できず、動きが破綻しやすい。 - OK例(自然言語記述):
A cinematic wide shot of a young woman running desperately through a rainy cyberpunk city street at night. The neon lights reflect on the wet pavement. The camera tracks alongside her, capturing her determined expression.
→ 文脈が明確で、AIは「映画のようなシーン」として一貫性のある動画を生成できる。

② 映像に命を吹き込む「カメラワーク用語」
動画生成において最も重要なのが「カメラの動き」の指定です。これを指定しないと、AIは「固定カメラ」なのか「手持ちカメラ」なのか迷ってしまい、結果として不自然に揺れる映像になりがちです。以下の映画用語をプロンプトの末尾に加えるだけで、クオリティが劇的に向上します。
| 用語 (英語) | 意味・効果 | おすすめの使用シーン |
|---|---|---|
| Slow Pan Right / Left | カメラをゆっくり左右に振る | 風景を見せたい時、横に移動する被写体を追う時 |
| Zoom In / Out | 被写体に寄る / 引く | キャラクターの表情を強調したい時、状況の全貌を見せたい時 |
| Tracking Shot | 動く被写体と一緒にカメラも移動する | 歩く/走る人物、走行する車など、アクションシーン全般 |
| Drone View / Aerial Shot | ドローンによる空撮視点 | 街並み、自然風景、壮大なオープニングカット |
| Static Camera | カメラを固定する(動かさない) | 被写体の微細な動き(瞬き、風になびく髪)だけを見せたい時 |
③ LLMベースモデル(Wan/Hunyuan)への最適化
2025年の主流であるWan 2.2やHunyuanVideoは、テキスト理解に高度なLLM(大規模言語モデル)を使用しています。そのため、AIに対しては「指示」というよりも「状況描写」を行うのがコツです。
例えば、「風が吹いている」と伝えたい場合、単に wind と書くよりも、以下のように具体的に書くことで、物理演算のようなリアルな挙動を引き出せます。
Her hair is fluttering violently in the strong wind.(彼女の髪が強風で激しくなびいている)Trees are swaying in the breeze.(木々がそよ風に揺れている)
このように、「何が(主語)+どう動いている(動詞)」という能動態の文章を作成することが、AIに正確な物理現象を理解させる鍵となります。
静止画でよく使う worst quality, low quality に加えて、動画では以下の要素を入れると安定します。
static, motionless, frozen, morphing, glitch, distorted, watermarks
特に「static(静止した)」や「motionless(動かない)」をネガティブに入れることで、動画全体に意図的に動きを出させることができます。
頻出エラーの対処法と軽量化テクニック
ローカル環境で動画生成を行っていると、避けて通れないのがエラーとの戦いです。生成ボタンを押して数十分待った挙句にアプリが落ちたり、謎の文字列が表示されて停止したりすることは、最先端技術を触っている証拠でもあります。
しかし、ComfyUIで発生するエラーの9割は、「メモリ(VRAM/RAM)不足」か「バージョン/設定の不整合」に集約されます。ここでは、初心者の心を折りがちな代表的なトラブルと、今すぐ実践できる具体的な解決策を解説します。
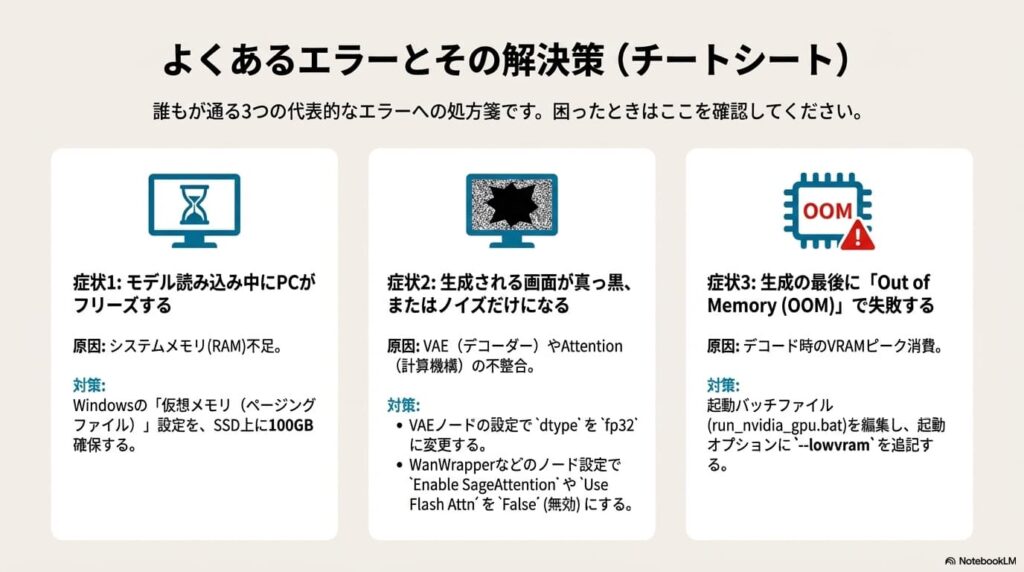
① ロードが終わらない / 「Loaded Partially」で止まる
モデルを読み込んでいる最中にPCの動作が極端に重くなり、コンソールに「Loaded Partially」と表示されたままフリーズする場合、原因はVRAMではなく「システムメモリ(RAM)の枯渇」である可能性が高いです。
Wan 2.1の14Bモデルなどは、VRAMに転送する前段階で、一時的に40GB〜60GBものデータをメインメモリに展開しようとします。物理メモリが32GB以下のPCではここで限界を迎えます。この問題を解決する唯一の無料テクニックが、Windowsの「仮想メモリ(ページングファイル)」の拡張です。
- Windowsの設定を開き、「システムの詳細設定」を検索して開く。
- 「詳細設定」タブ > パフォーマンスの「設定」 > 「詳細設定」タブ > 仮想メモリの「変更」をクリック。
- 「すべてのドライブのページングファイルのサイズを自動的に管理する」のチェックを外す。
- SSD(空き容量に余裕があるドライブ)を選択し、「カスタムサイズ」にチェックを入れる。
- 「初期サイズ」と「最大サイズ」の両方に「100000」(約100GB)と入力し、「設定」ボタンを押してOKで閉じる。
- PCを再起動する。
これにより、SSDの一部をメモリ代わりに使用できるようになります。速度は遅くなりますが、「動かない」状態から「時間はかかるが動く」状態へと劇的に改善します。
② 生成結果が真っ暗(Black Screen)になる
プレビュー画面が真っ黒、あるいはノイズだらけの緑色になる場合、原因は主に「計算精度の不一致」か「最適化機能の相性」です。
- VAEのデコード失敗: 動画の生成(潜像)までは成功しているが、それを映像に戻す「VAE Decode」で失敗しているケースです。VAEモデルがFP16精度に対応していない古いGPUを使っている場合は、VAEロード時の設定で
dtypeをfp32に強制するか、vae_tile_sizeを小さく(例: 256)設定してください。 - SageAttention / FlashAttentionの不具合: WanWrapperなどのカスタムノードには、高速化のために「SageAttention」などの最新技術が組み込まれています。しかし、ドライバのバージョンやGPU世代によってはこれが悪さをして黒画面になります。ノードの設定画面で「Enable SageAttention」や「Use Flash Attn」を False(無効)にすることで直る場合が大半です。
③ 最後の最後で落ちる「OOM (Out of Memory)」対策
生成プロセスが100%まで進んだ瞬間に「CUDA Out of Memory」と出て落ちる現象。これは、完成した巨大な動画データをVRAM上で展開しようとして容量オーバーになる「デコード死」です。
これを防ぐには、ComfyUIの起動バッチファイル(run_nvidia_gpu.bat)を編集し、起動引数を追加してメモリ管理を厳格化するのが有効です。
| 起動引数 (Arguments) | 効果と副作用 | 推奨ユーザー |
|---|---|---|
--lowvram |
VRAMの使用を最小限に抑え、積極的にメインメモリへデータを逃がす。 | VRAM 8GB〜12GBのユーザー (速度は大幅に低下する) |
--novram |
VRAMを一切計算に使わず、全てCPUで処理する(ほぼ動かないレベルで遅い)。 | 最終手段(非推奨) |
--disable-smart-memory |
ComfyUIのメモリ自動管理を無効化し、強制的にアンロードさせる。 | 特定のワークフローでエラーが出る場合 |
動画生成は、ゲーミングベンチマークを数十分回し続けるのと同じくらいGPUに負荷をかけます。VRAM温度が100℃近くに達することも珍しくありません。エラーの原因が「熱暴走によるサーマルスロットリング」であることも多いため、ケースファンを全開にする、部屋のエアコンを入れるなど、ハードウェアの冷却にも気を配ってください。
Stable Diffusionの動画生成はローカルが最適解
ここまで解説してきたように、ローカル環境での動画生成には、環境構築の手間やハイスペックなPCが必要というハードルは確かに存在します。しかし、それらを乗り越えた先には、誰にも邪魔されない、完全に自由な創作のフロンティアが待っています。
RunwayやLumaといったクラウドサービスは手軽ですが、「暴力表現や性的表現への過度な検閲」「プロンプトが拒否されるストレス」「生成枚数ごとの課金によるコストの増大」といった制約が常につきまといます。一方、ローカル環境では、あなたがルールの全てです。どのような表現を試みようと自由ですし、納得いくまで何度でも、何百回でも無料で生成(リテイク)を繰り返すことができます。
さらに、ControlNetを使ってキャラクターのポーズをミリ単位で指定したり、自分だけのLoRAモデルを作って画風を統一したりといった高度な制御は、現状ローカル環境でしか実現できないレベルのものです。技術は日々進化していますが、今こそ自分のPCに最強の動画生成環境を構築して、映像制作の新しい世界へ飛び込んでみてはいかがでしょうか。

※本記事で紹介したソフトウェアやモデルの導入は、ユーザー自身の責任において行ってください。ハードウェアの相性やバージョンアップにより、手順や挙動が記事の内容と異なる場合があります。
{kind=link}